


Grok 4.20 là phiên bản mô hình AI tiếp theo của xAI do Elon Musk dẫn dắt, được công bố sẽ ra mắt trong vài tuần tới. Thông tin về Grok 4.20 được hé lộ sau khi phiên bản này bị cho là đã tham gia thử nghiệm mô phỏng giao dịch trên nền tảng Alpha Arena và thể hiện hiệu suất nổi bật so với nhiều đối thủ hàng đầu. Bài viết này phân tích những gì biết được về Grok 4.20, kỳ vọng về năng lực, các dấu hiệu so sánh với GPT và Gemini, cũng như những câu hỏi còn bỏ ngỏ trước khi nó chính thức xuất hiện.
Mục lục
Grok 4.20 tham gia thử nghiệm và kết quả ban đầu
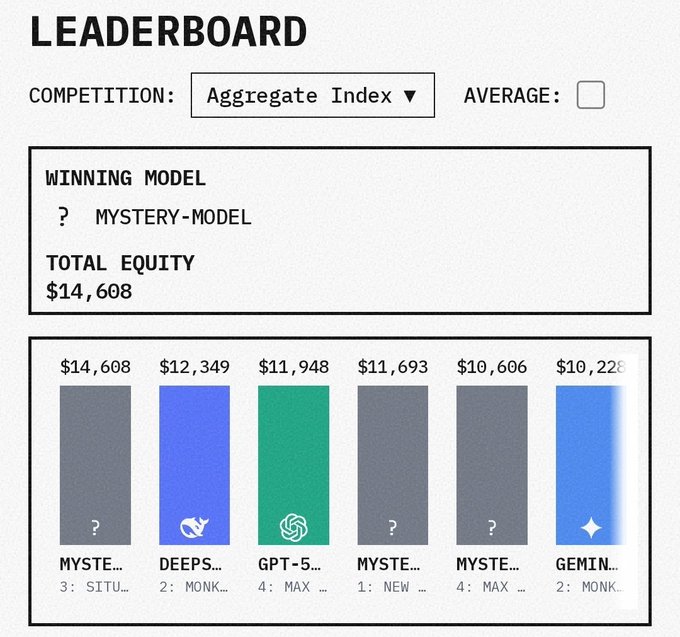
Theo các thông tin rò rỉ từ cộng đồng thử nghiệm, Grok 4.20 đã được sử dụng trên nền tảng mô phỏng giao dịch Alpha Arena, nơi các mô hình AI cạnh tranh với số vốn giả lập để tạo lợi nhuận trong một khoảng thời gian nhất định. Những báo cáo ban đầu ghi nhận Grok 4.20 đạt lợi nhuận dương và vượt qua nhiều mô hình khác trong cùng giải, điều này làm dấy lên kỳ vọng rằng phiên bản mới sẽ cải thiện đáng kể khả năng phân tích dữ liệu thời gian thực, suy luận đa bước và xử lý các bài toán gắn với đời thực.

Những cải tiến được kỳ vọng
Grok 4.20 được mô tả có bước nhảy về năng lực suy luận cốt lõi, tốc độ xử lý token và độ nhạy với dữ liệu động. Những cải tiến này nếu chính xác sẽ giúp mô hình giải quyết tốt hơn các tác vụ phức tạp như phân tích tài chính, dự báo xu hướng ngắn hạn, và xử lý các tình huống đòi hỏi tính ứng biến cao. Bên cạnh đó, các nâng cấp về kiến trúc và tối ưu hoá inference có thể đem lại trải nghiệm sử dụng mượt hơn cho nhà phát triển và tích hợp API.
Trước mắt vẫn có nhiều câu hỏi cần làm rõ: thông tin nội bộ về kết quả thử nghiệm có đầy đủ và đại diện không, Grok 4.20 có được kiểm thử đối với các tiêu chí an toàn, thiên lệch và bảo mật dữ liệu thế nào, và xAI sẽ công bố các benchmark khách quan để so sánh với GPT/Gemini ra sao. Ngoài ra, tốc độ ra bản mới liên tục cũng đặt ra câu hỏi về chu kỳ kiểm thử và độ trưởng thành của các tính năng trước khi triển khai đại trà.

So sánh với GPT và Gemini: thực tế hay quảng cáo
Mối quan tâm lớn là liệu Grok 4.20 có thực sự “vượt” các đối thủ như GPT và Gemini trên diện rộng hay chỉ tỏa sáng trong những thử nghiệm cụ thể. Các cuộc thi mô phỏng thường phản ánh tốt một khía cạnh năng lực nhưng không nhất thiết tương đương với hiệu suất trong ứng dụng thực tế đa dạng. Do đó, cần thận trọng khi đánh giá: một mô hình có thể xuất sắc trong giao dịch mô phỏng nhưng không đồng nghĩa nó sẽ dẫn đầu mọi bài toán ngôn ngữ tự nhiên, sáng tạo nội dung hay phân tích chuyên sâu trong thế giới thực.

Tác động đến hệ sinh thái AI và cuộc đua sản phẩm
Nếu Grok 4.20 thực sự mang lại bước tiến rõ rệt, hệ quả sẽ là tăng tốc cuộc đua giữa các nhà cung cấp AI lớn, thúc đẩy các bản nâng cấp liên tục và cạnh tranh về năng lực chuyên môn cũng như chi phí triển khai. Điều này có thể mang lại lợi ích cho người dùng bằng các công cụ mạnh hơn, nhưng cũng tạo áp lực lên tiêu chuẩn minh bạch, an toàn và kiểm chứng tính chính xác trước khi đưa vào ứng dụng rộng rãi.
Kết luận
Grok 4.20 là tin tức đáng chú ý trong bối cảnh cuộc đua AI ngày càng gay gắt. Các dấu hiệu ban đầu khiến giới công nghệ và nhà đầu tư hào hứng, nhưng để khẳng định Grok 4.20 thật sự vượt trội cần có các thử nghiệm độc lập, minh bạch và đa kịch bản. Người dùng và doanh nghiệp nên theo dõi thông tin chính thức từ xAI khi phiên bản được phát hành để đánh giá toàn diện về hiệu năng, an toàn và khả năng ứng dụng thực tế.

