


Vision Language Model (VLM) là bước tiến đột phá của trí tuệ nhân tạo, kết hợp giữa Xử lý ngôn ngữ tự nhiên (NLP) và Thị giác máy tính (Computer Vision). Trong những năm gần đây, hai lĩnh vực này đã phát triển mạnh mẽ, giúp máy móc không chỉ “đọc hiểu” văn bản mà còn “nhìn thấy” và phân tích hình ảnh. Sự kết hợp đó chính là nền tảng tạo ra các mô hình VLM – cho phép AI xử lý đồng thời dữ liệu hình ảnh và ngôn ngữ một cách hiệu quả và tự nhiên.
Mục lục
Vision Language Model là gì?
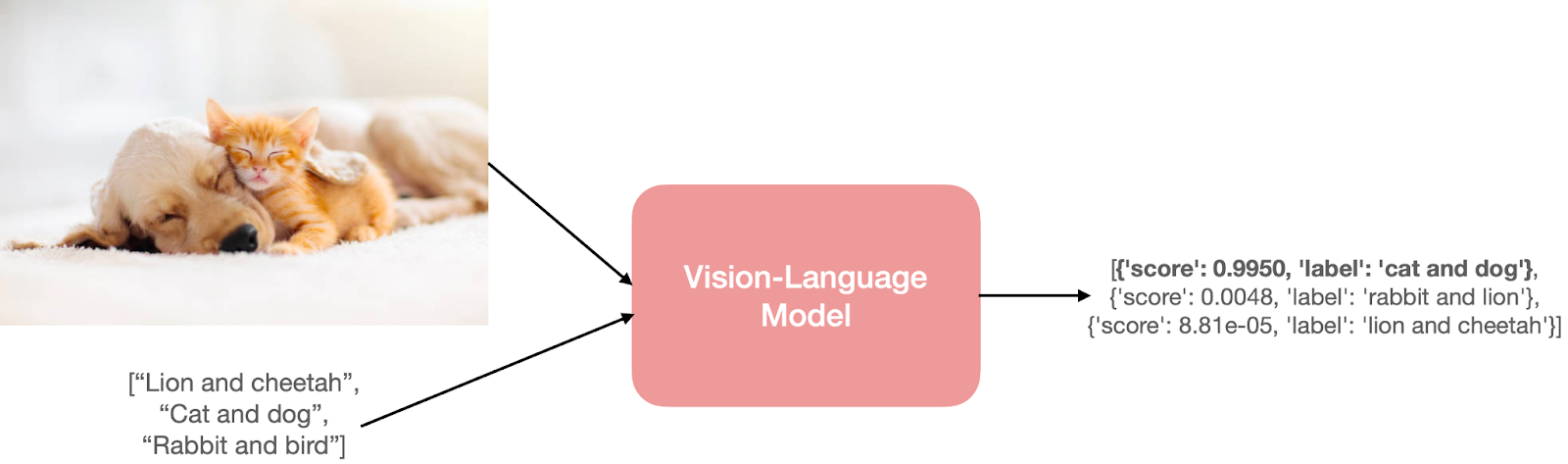
Vision Language Model (VLM) là hệ thống AI tích hợp giữa mô hình ngôn ngữ lớn (LLM) như GPT, LLaMA và bộ mã hóa hình ảnh (Vision Encoder). Nhờ đó, VLMs không chỉ phản hồi văn bản như các chatbot thông thường mà còn có thể “nhìn” ảnh hoặc video, hiểu nội dung và đưa ra câu trả lời dựa trên cả hai nguồn dữ liệu.
Người dùng có thể gửi một bức ảnh, video hoặc tài liệu hình ảnh kèm câu hỏi, và VLM sẽ xử lý toàn bộ ngữ cảnh để phản hồi chính xác bằng văn bản.
Vì sao VLM quan trọng?
Trước đây, các mô hình Computer Vision truyền thống như CNN thường bị giới hạn ở các tác vụ cụ thể: phân loại hình ảnh, nhận diện khuôn mặt hoặc ký tự. Tuy nhiên, khi có yêu cầu mới, mô hình cần huấn luyện lại từ đầu – tốn kém thời gian và tài nguyên.
VLMs khắc phục hoàn toàn điểm yếu đó bằng khả năng:
- Trả lời câu hỏi dựa trên hình ảnh/video (Visual Q&A)
- Đọc hiểu văn bản viết tay hoặc in trên tài liệu, hóa đơn
- Tóm tắt nội dung ảnh, video dài hoặc nhiều ảnh cùng lúc
- Linh hoạt thay đổi nhiệm vụ chỉ bằng cách thay prompt đầu vào
Nhờ đó, VLMs được đánh giá là bước đột phá trong AI đa phương thức (Multimodal AI).
VLM hoạt động như thế nào?
Một mô hình VLM điển hình gồm 3 thành phần chính:
- Vision Encoder: Mã hóa hình ảnh thành thông tin số. Thường dùng kiến trúc CLIP để ánh xạ ảnh và văn bản vào cùng không gian ngữ nghĩa.
- Projector: Chuyển đầu ra của Vision Encoder thành định dạng mà LLM có thể hiểu (image tokens).
- LLM (Large Language Model): Tiếp nhận prompt (bao gồm cả ảnh và văn bản) và tạo phản hồi.
Người dùng tương tác với VLM tương tự như trò chuyện với chatbot AI, nhưng có thể chèn thêm hình ảnh hoặc video để mô hình hiểu sâu hơn về ngữ cảnh.
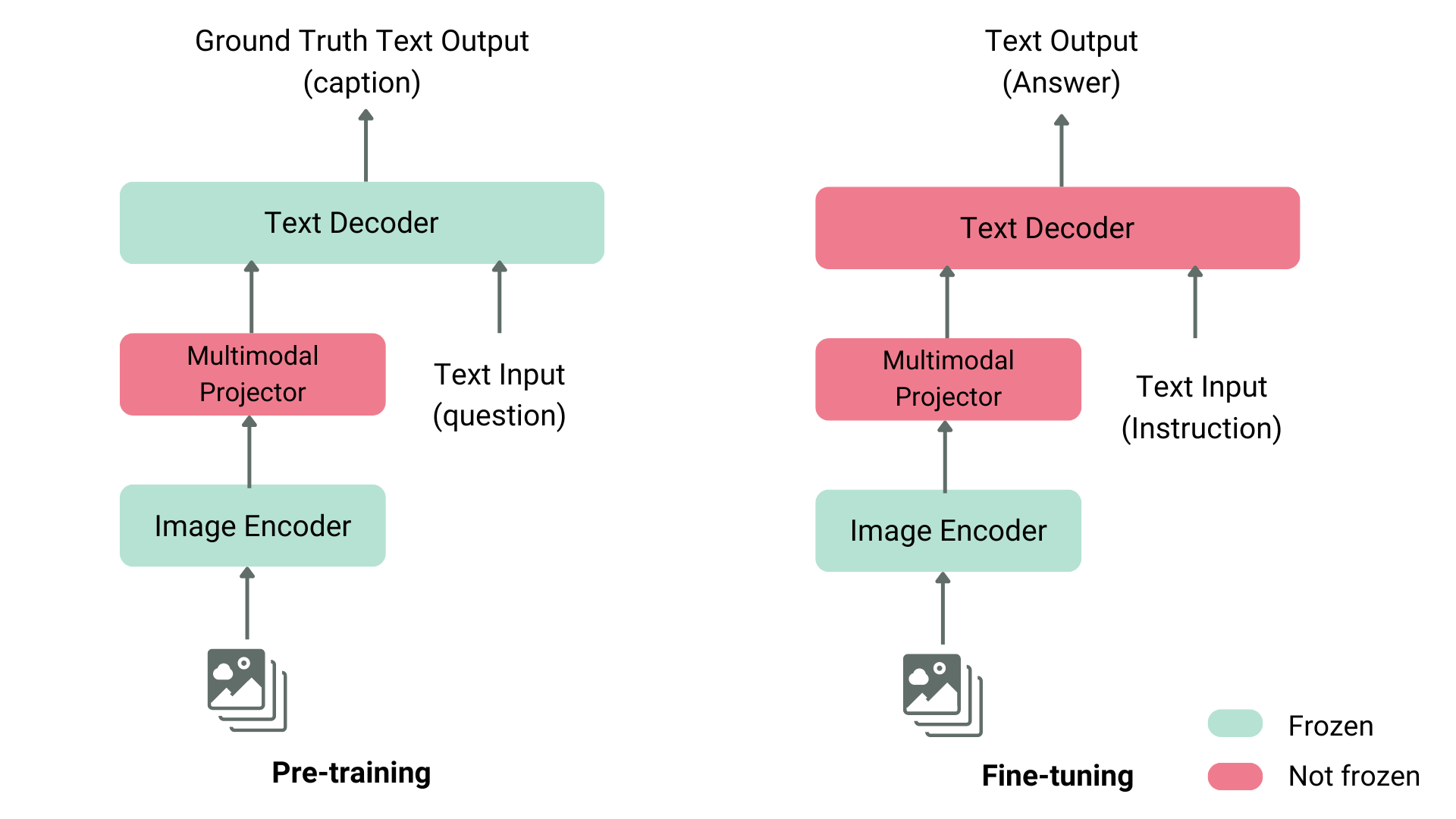
Quy trình huấn luyện Vision Language Models
Quá trình huấn luyện VLM thường trải qua 3 giai đoạn chính:
1. Pretraining (Trước huấn luyện)
Huấn luyện trên tập dữ liệu lớn gồm các cặp ảnh – văn bản, giúp mô hình học cách liên kết và hiểu hai dạng dữ liệu.
2. Supervised Fine-Tuning (Tinh chỉnh có giám sát)
Cung cấp các ví dụ thực tế với prompt và phản hồi mẫu để mô hình học cách trả lời đúng.
3. PEFT (Parameter Efficient Fine-Tuning)
Tinh chỉnh mô hình nhanh chóng, tiết kiệm tài nguyên, giúp VLM thích nghi với dữ liệu riêng của từng doanh nghiệp.
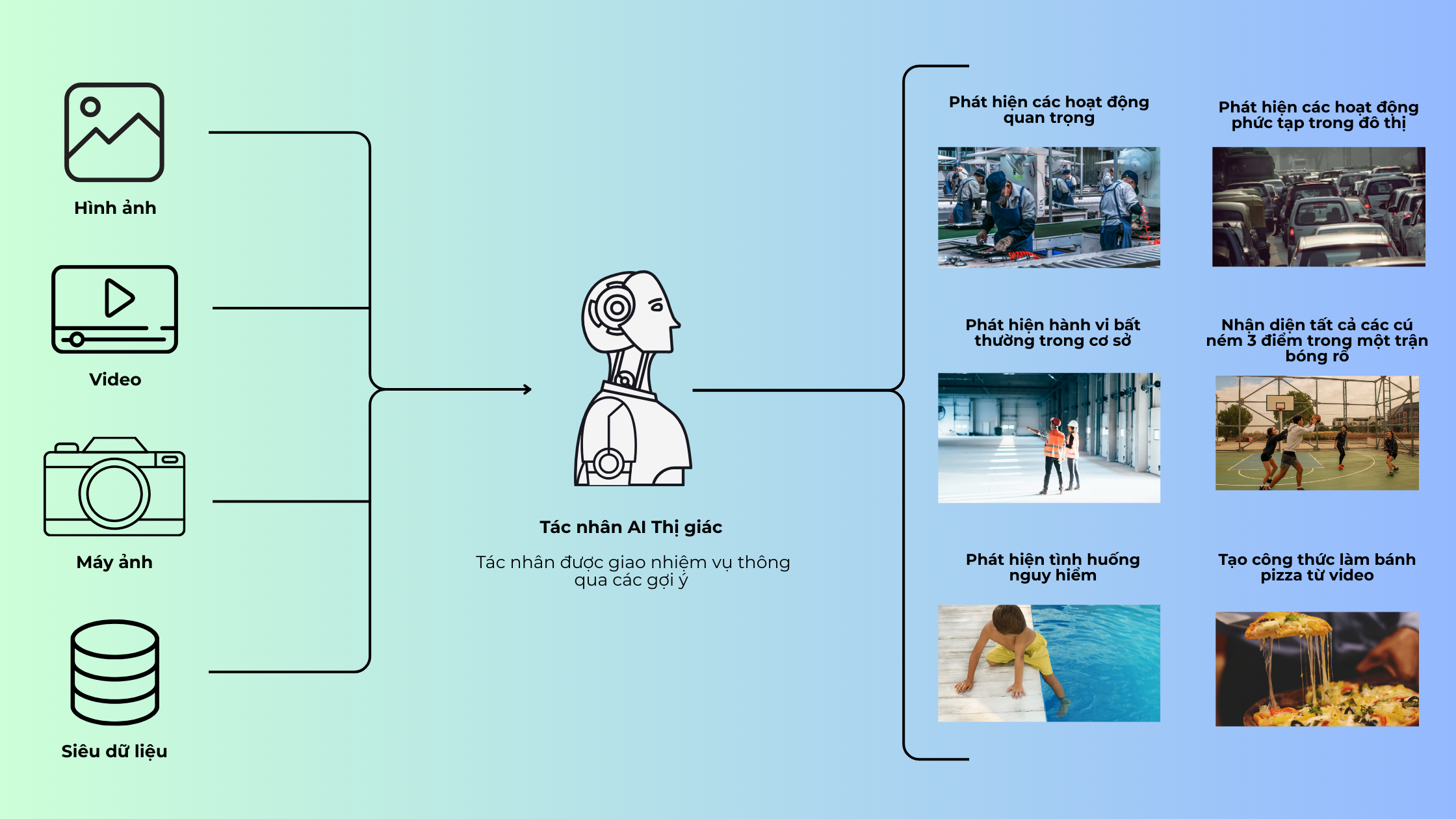
Ứng dụng nổi bật của Vision Language Model
Với khả năng xử lý cả hình ảnh và ngôn ngữ, VLMs đang được ứng dụng mạnh mẽ trong nhiều lĩnh vực:
- Bán lẻ: Phân tích hình ảnh camera, phát hiện kệ trống, hành vi khách hàng.
- Giáo dục: Đọc đề toán viết tay và hướng dẫn giải chi tiết.
- Tài chính – doanh nghiệp: Tự động đọc và phân tích hóa đơn, tài liệu scan.
- Y tế: Phân tích hình ảnh chẩn đoán, đọc phim X-quang.
- Giao thông: Nhận diện sự cố qua camera – như tai nạn, vật cản.
- Truyền thông – thể thao: Tạo bình luận, tóm tắt video trận đấu.
Tương lai của VLMs trong AI đa phương thức
Vision Language Models đang mở ra một kỷ nguyên mới cho AI đa phương thức thông minh – nơi máy móc có thể hiểu cả hình ảnh và ngôn ngữ, từ đó phản hồi linh hoạt và tự nhiên như con người.
Trong tương lai, VLM có thể là nền tảng cho các AI Agent thông minh – tự động hóa quy trình từ giám sát hình ảnh, sáng tạo nội dung đến hỗ trợ khách hàng.

